- 2021 GDSC Sookmyung 3분기 스터디: DeepSleep팀 논문 리뷰 스터디 1주차
- 주제: Imagenet classification with deep convolutional neural networks (AlexNet)
- 링크: http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
- 배경
- 현재 MNIST 분류기의 인식 능력(에러 발생률 0.3% 이하)은 인간의 성능만큼 뛰어나지만, 현실의 사물들은 훨씬 더 다양성을 갖추고 있으므로 더 큰 크기의 학습 데이터가 필요
- LabelMe, ImageNet 등 매우 큰 규모의 이미지 데이터베이스의 등장
- 이미지의 특성에 대해 강력한 추론을 할 수 있으며, 훈련하기도 쉬운 CNN을 사용 (다만 성능은 standard feedforward NN보다 조금 나쁠 수 있음)
- ILSVRC-2010과 ILSVRC-2012에서 CNN을 이용한 모델(AlexNet)로 우승
- 주요 내용
- AlexNet의 네트워크 성능 향상과 훈련 속도 단축 방법
- AlexNet의 Overfitting을 방지하기 위한 기법
- AlexNet의 구조
Architecture

총 8개의 레이어 사용: 5 conveolutional layers + 3 fully-connected layers
1) ReLU Nonlinearity
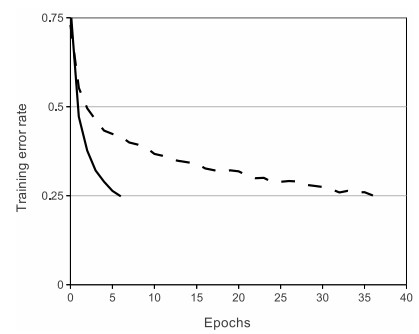
tanh활성함수 대신RelU(Rectified Linear Units)활성함수 사용- ReLU와 tanh의 성능 비교
- Training error rate가 0.25에 도달하기까지 걸리는 시간 비교
- tanh를 사용했을 때보다 ReLU를 사용했을 때가 6배 더 빠름
2) Training on Multiple GPUs
- 한 개의 GTX 580 GPU만 사용하기에는 데이터의 개수가 너무 많으므로 2개의 GPU를 병렬로 이어 각 GPU에 네트워크를 분산시킴
- GPU가 특정 레이어에서만 소통하도록 함
- 예를 들어, 3번째 레이어는 2번째 레이어의 모든 커널 맵으로부터 입력을 받도록 하고, 4번째 레이어는 3번째 레이어 중 같은 GPU에 있는 커널 맵만 입력으로 받도록 함.
- 연결 패턴을 선택하는 건 cross-validation을 통해 결정
- 이 방식을 통해 top-1, top-5 error rate를 각각 1.7%, 1.2%까지 감소시킴
- two-GPU net을 사용하는 것이 one-GPU net을 사용하는 것보다 조금 더 적은 시간이 소요됨
3) Local Response Normalization
- ReLU의 특징 중 하나가 포화(saturation)를 막기 위한 input normalization을 필요로 하지 않는다는 것
- 그럼에도 불구하고(?) generalization을 위해 local normalization을 사용
- ReLU는 양수 입력을 받으면 그대로 출력하기 때문에 Pooling 등을 할 때 매우 높은 하나의 픽셀 값이 주변의 픽셀에 영향을 주는 현상이 발생함. 이것을 방지하기 위해 다른 활성화 맵의 같은 위치에 있는 픽셀끼리 normalization을 해줌

- 참고: https://taeguu.tistory.com/29
4) Overlapping Pooling
- CNN에서의 Pooling: 특성 맵의 크기를 줄이기 위해 같은 커널 맵 안의 인접한 뉴런 그룹끼리 묶어 출력을 축약하는 것
- Overlapping Pooling: 커널의 보폭(stride)를 커널의 크기보다 크게 하여 움직이도록 하는 것. Non-overlapping pooling과 비교했을 때 top-1, top-5 error rate가 더 작게 나온다.

- 이미지 출처: https://bskyvision.com/421
전체적인 구조
Convolutional Layers
- 첫번째 레이어: 224x224x3 크기의 이미지를 입력으로 받아 11x11x3 크기의 stride=4인 커널 96개로 55x55x96 크기의 특성맵을 출력한다. Pooling과 LRN이 적용되며 ReLU 활성화 함수를 사용한다.
- 두번째 레이어: 5x5x48 크기의 커널 256개로 27x27x256 크기의 특성맵을 출력한다. Pooling과 LRN이 적용되며 ReLU 활성화 함수를 사용한다.
- 세번째 레이어: 3x3x356 크기의 커널 384개로 13x13x384 크기의 특성맵을 출력한다. 세번째 레이어부터는 Pooling과 LRN을 적용하지 않는다. 활성화 함수로 ReLU를 사용한다.
- 네번째 레이어: 3x3x192 크기의 커널 384개로 13x13x192 크기의 특성맵을 출력한다. 활성화 함수로 ReLU를 사용한다.
- 다섯번째 레이어: 3x3x192 크기의 커널 256개로 13x13x256 크기의 특성맵을 출력한다. 활성화 함수로 ReLU를 사용한다.
Fully-connected Layers
- 각각 4096개의 뉴런을 갖는다.
Reducing Overfitting
1) Data Augmentation
과적합을 피하는 방법 중 가장 쉽고 흔한 방법은 데이터의 크기를 키우는 것이다. 이 논문에서는 데이터의 크기를 키우기 위해 가지고 있는 데이터를 변형하여 사용했다. 파이썬 코드를 통해 이미지를 변형시키며, GPU에서 이미지를 학습시키는 동안 파이썬 코드로 CPU를 사용해 이미지를 변형하므로 computationally free하다.
- 데이터 확대의 첫번째 형식은 이미지 변형과 수평 반전이다. 256x256 크기의 이미지로부터 224x224 크기의 조각 이미지를 만들고, 각각의 조각에 대해 수평 반전된 이미지 또한 데이터셋에 추가시키는 방법으로 데이터셋을 키웠다.
label preserving transformations: 원본 데이터의 특성을 그대로 보존한 transformations 방법. 예를 들어 6을 상하반전 시키면 9가 되는데, 이 경우는 label이 보존되지 못한 것
- 두번째 형식은 이미지의 채도를 바꾸는 것이다.
2) Dropout
hidden neuron의 출력값을 0.5의 확률로 0으로 만드는 것이다. "dropped-out"된 뉴런은 다음 단계의 레이어에 아무런 영향을 주지 않으며, backpropagation 대상에서 제외된다. Dropout 기술은 한 뉴런이 다른 특정 뉴런에 의지할 수 없게 만듦으로써 뉴런간 상호적응력을 감소시킨다. 따라서, 다양한 뉴런의 조합을 사용하여 특징을 더 강력하게 학습할 수 있게 된다.
test 시에는 모든 뉴런을 사용했지만 출력에 0.5를 곱해 사용했다. 이는 기하급수적으로 많은 Dropout 네트워크에 의해 생성된 예측 분포의 기하학적 평균을 취하는 합리적인 근사치다. 첫 2개의 fully-connected layer에 dropout 기법을 사용했다.