![[NLP] Google의 BERT 이해하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FemKM2h%2Fbtrq69SB0j8%2FBC4oGPlf1grsVYSuimVJnk%2Fimg.png)
BERT란 무엇인가
BERT(Bidirectional Encoder Representation from Transformer) : Google에서 만든 문맥을 고려한 Transformer 기반 고성능 텍스트 임베딩 모델.
임베딩 모델이 문맥을 고려할 때의 장점
👉🏻 다의어∙동음이의어를 구분할 수 있다.
A: He got bit by Python(파이썬이 그를 물었다).
B: Python is my favorite programming language(내가 제일 좋아하는 프로그래밍 언어는 파이썬이다).
- Word2Vec:
정적 임베딩, A에서의 'Python' 임베딩 == B에서의 'Python' 임베딩 - BERT:
동적 임베딩, 트랜스포머 모델 기반이므로 문장의 각 단어를 문장 내 모든 단어들과 연결시켜 문맥을 이해할 수 있다. A에서는 'Python-bit'과의 관계에 주목, B에서는 'Python-programming' 관계에 주목하여 서로 다른 임베딩 값을 갖는다.
BERT의 동작 방식
트랜스포머 모델을 기반으로 하지만, 트랜스포머의 인코더-디코더 구조에서 인코더만 사용한다. 인코더는 문장을 입력받아 문맥을 고려해 문장의 의미를 학습하여 각 단어의 문맥 표현을 출력했다.

문장이 인코더의 입력으로 들어오면 인코더는 멀티 헤드 어텐션 메커니즘으로 단어끼리 모두 연결하여 관계와 문맥을 파악해 문장 각 단어의 문맥 포현을 출력한다. 인코더는 여러 개 쌓을 수 있으며, 각 단어 토큰의 표현 크기는 인코더 레이어 출력의 차원이다.
BERT의 구조
BERT는 크기에 따라 아래의 두 모델로 나뉜다.
- BERT-base: OpenAI GPT와 동일한 하이퍼파라미터를 가짐. GPT와의 성능 비교를 위해 설계됨
- BERT-large: BERT의 최대 성능을 보여주기 위해 만들어짐

GLUE Results
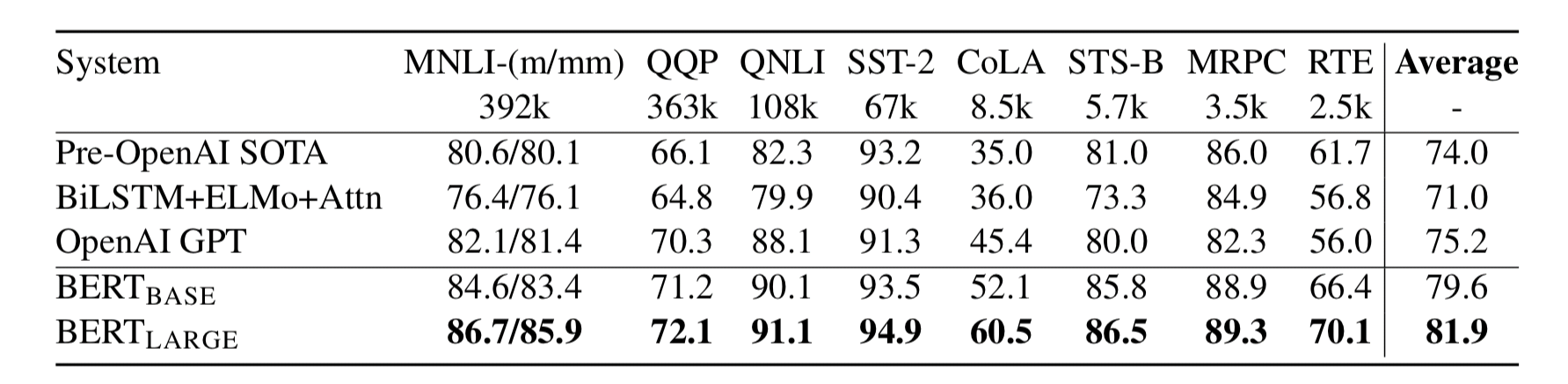
- 모든 task에 대해 SOTA 달성
- BERT-large가 일반적으로 BERT-base보다 성능이 좋음
- 사전학습 덕분에 데이터셋의 크기가 작아도 모델의 크기가 클수록 정확도가 상승
BERT 사전 학습
BERT에 데이터를 입력하기 전에 세 가지 임베딩 레이어를 통해 입력 데이터를 임베딩으로 변환해야 한다.
입력 임베딩
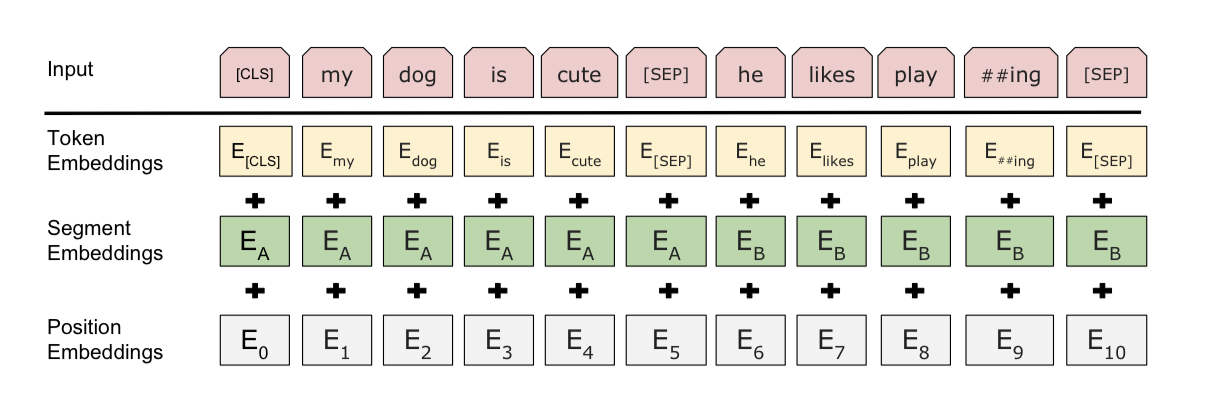
- 토큰 임베딩(token embedding)
- 세그먼트 임베딩(segement embedding)
- 위치 임베딩(position embedding)
토큰 임베딩
- 문장 쌍(Sentence pair)은 합쳐져서 단일 시퀀스로 입력되며, 입력 내의 쌍은 한 개 혹은 두 개의 문장으로 이루어져 있을 수 있다.
- 예시: QA Task - [Question(1문장), Paragraph(2문장)]
- Q: What is your favorite programming language?
- A: My favorite programming language is Python. It's easy to use.
- 예시: QA Task - [Question(1문장), Paragraph(2문장)]
- Sentence의 시작 부분에
[CLS]라는 토큰을 추가한다.- 분류 문제를 풀 때만 사용되지만 다른 문제를 풀더라도 무조건 추가해야 한다.
- Sentence 내 모든 문장의 끝에
[SEP]라는 새 토큰을 추가한다. - 토큰 임베딩을 거친 후의 형태:
tokens = [[CLS], My, favorite, ... , [SEP], It's, ..., use, [SEP]]
워드피스 토크나이저
BERT에서 사용하는 토크나이저는 단어를 더 작은 단위로 쪼개 토큰화하는 서브워드 토크나이저 기반의 워드피스 토크나이저다. 단어를 더 작은 단위로 쪼개 토큰화했을 때의 장점은 다음과 같다:
- OOV(out-of-vocabulary)의 처리가 쉬워진다. 단어가 어휘 사전에 없으면 계속해서 하위 단어로 쪼개가며 개별 문자에 도달할 때까지 확인하기 때문이다.
- 계산 비용을 비교적 작게 유지할 수 있다. 텍스트 데이터를 학습한 모델의 크기는 Vocabulary의 크기에 영향을 받고 이 크기에 비례하여 계산비용이 증가하는데, 하위 단어로 쪼개 토큰화하면 Vocabulary의 크기를 작게 유지할 수 있다.
- 고유의 알고리즘 덕분에 언어에 상관없이 범용적으로 적용할 수 있다.
워드피스 토크나이저는 어떻게 동작하는가?
워드피스 토크나이저가 처음으로 등장한 논문의 설명에 따르면 다음과 같은 알고리즘을 따라 동작한다.
- 기본 글자들(알파벳 등)으로 단어 유닛 인벤토리를 초기화한다.
- 1에서 생성된 단어 인벤토리를 사용해 훈련 데이터로 언어 모델을 만든다.
- 현재의 단어 인벤토리에서 두 개의 유닛을 결합해 새로운 단어 유닛을 생성한다. 이 때 선택되는 두 단어는 결합했을 때의 가능도(likelihood) 상승폭이 가장 큰 단어들이다. 👉🏻 모수 추정을 위해 ML(maximize likelihood) 사용
- 미리 정해둔 단어 인벤토리 크기 한도에 도달하거나 가능도의 증가폭이 특정 임계점 아래로 내려갈 때까지
Goto 2-> 반복
가능도(likelihood): 어떤 값이 관측되었을 때, 이것이 어떤 확률 분포에서 왔을지에 대한 확률
세그먼트 임베딩
- 같은 문장 내의 서로 다른 두 작은 문장을 구별하는 데 사용된다.
- 두 문장을 구분하기 위해
[SEP]토큰 사용에 추가로 세그먼트 임베딩을 사용해서 앞의 문장에는sentence A embedding, 뒤의 문장에는sentence B embedding을 더해준다. - 문장이 하나라면
sentence A embedding만을 사용한다.
위치 임베딩
- BERT의 베이스가 되는 트랜스포머는 모든 단어를 병렬로 처리하므로 단어의 순서에 대한 정보를 따로 제공해 줘야 한다. 위치 임베딩을 통해 문장의 각 토큰에 대한 위치 임베딩 출력을 얻을 수 있다.
- BERT는 트랜스포머와 다르게 학습을 통해 위치 정보를 얻는 포지션 임베딩을 사용한다. 문장의 길이만큼의 포지션 임베딩 벡터를 학습시켜 사용한다.
사전학습에 대한 기존 방법론
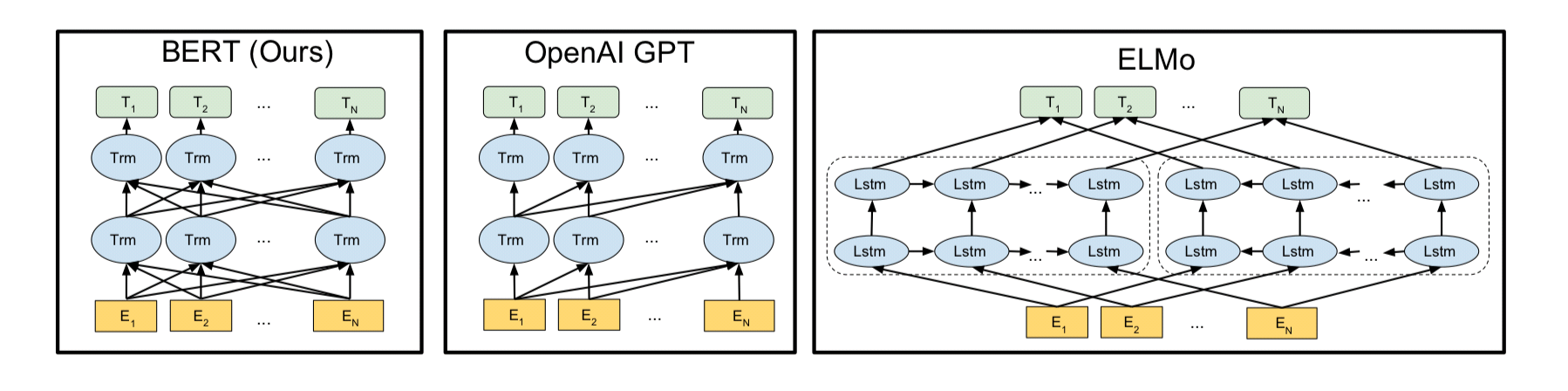
- 전통적인 언어 모델링(Language Modeling): n-gram, 앞의 N-1개의 단어로 뒤에 올 단어를 예측하는 모델
- 필연적으로 단방향일수 밖에 없고, BiLM을 사용하는 ELMo더라도 순방향, 순방향의 언어 모델을 둘 다 학습해 활용하지만, 단방향 언어 모델의 출력을 concat하여 사용하는 정도이므로 제한적인 양방향성을 가짐
BERT 사전학습에 사용된 새로운 방법론
- Masked Language Model(MLM)
- Next Sentence Prediction(NSP)
마스크 언어 모델링 Masked Language Model
BERT는 양방향성을 MLM을 통해 구현했다. MLM은 자동 인코딩 언어 모델로, 예측을 위해 문장을 양방향으로 읽는다. 전체 단어의 15%를 무작위로 마스킹하고, 마스크된 단어를 예측하도록 모델을 학습하며 문맥을 파악하는 능력을 향상시킨다. 마스크된 단어를 예측하기 위해 모델은 양방향으로 문장을 읽고 마스킹된 단어를 예측하려 시도한다. [MASK] 토큰은 사전학습에서만 사용되며, 파인 튜닝 시에는 사용되지 않는다.
15%의 토큰을 무작위로 마스킹할 때 80-10-10% 규칙을 적용한다.
- 80%: 토큰을
[MASK]로 바꾼다.- 예)
So we could call it even->So we could [MASK] it even
- 예)
- 10%: 토큰을 임의의 토큰(단어)로 바꾼다.
- 예)
So we could call it even->So we could pizza it even
- 예)
- 10%: 어떠한 변경도 하지 않는다. BERT는 이 단어가 변경된 단어인지 원래 단어인지 모르므로 BERT가 원래 단어가 무엇인지 예측하도록 한다.
전체 단어 마스킹 Whole Word Masking
전체 단어 마스킹은 단어를 무작위로 마스킹하는 과정에서 하위 단어가 선택되었을 때, 해당 하위 단어와 관련된 모든 단어를 마스킹하는 방법이다. 아래는 WWM의 동작 예시다.
#1
tokens = [[CLS], let, us, start, pre, ##train, ##ing, the, model, [SEP]]
#2 - ##train이 마스킹됨
tokens = [[CLS], let, us, start, pre, [MASK], ##ing, the, model, [SEP]]
#3 - ##train과 관련된 pre와 ##ing도 마스킹됨
tokens = [[CLS], let, us, start, [MASK], [MASK], [MASK], the, model, [SEP]]마스킹된 하위 단어(예시에서는 ##train)와 관련된 모든 단어를 마스킹하는 동안 마스크 비율(15%)을 초과하면 다른 단어의 마스킹을 무시한다.
마스크된 토큰 예측

토큰화와 WWM을 거친 후에 입력 토큰을 토큰, 세그먼트, 위치 임베딩 레이어에 입력해 입력 임베딩을 얻을 수 있다. 이 입력 임베딩을 BERT에 제공하면 BERT는 각 토큰의 표현 $R$을 출력한다. 각 단어들의 표현들($R$) 중 마스크된 토큰의 표현 벡터 $R_{[MASK]}$을 소프트맥스 활성화를 통해 피드포워드 네트워크에 입력하면, 그 출력으로 각 단어가 [MASK] 자리에 있어야 할 단어일 확률을 반환한다.
다음 문장 예측 Next Sentence Prediction
QA, Natural Language Inference(NLI)처럼 NLP 태스크 중에선 두 문장 사이의 관계를 이해하는 것이 중요한 것들이 있는데, 이것은 전통적인 언어 모델링(n-gram)에서 학습될 수 없는 부분이다. 따라서 BERT는 NSP라고 불리는 두 문장을 입력하고 두번째 문장이 첫번째 문장의 다음 문장인지 예측하는 이진 분류 테스트를 수행한다.
- 학습을 위해 50%는 실제로 이어지는 두 문장을 넣는다.
- 나머지 50%은 랜덤으로 추출된 두 문장을 넣는다.
이진 분류를 위해 레이블링 작업이 필요하다. 서로 이어지는 문장 쌍에는 IsNext 레이블을 붙이고, 서로 이어지지 않는 문장 쌍에는 NotNext 레이블을 붙여 두 문장이 이어지지 않음을 표시한다.
[CLS] He got [MASK] by Python [SEP] So now he's bleeding LABEL = IsNext[CLS] He got [MASK] by Python [SEP] Let's go out and get some pizza LABEL = NotNext
예측을 위해서는 [CLS] 토큰의 표현값을 사용한다. [CLS]는 문장 내 다른 단어들과의 self-attention을 통해 모든 토큰의 집계 표현을 담고 있기 때문이다. (참고) [CLS] 토큰에 classification layer를 붙이고 softmax를 통해 각 레이블에 속할 확률을 계산한다.
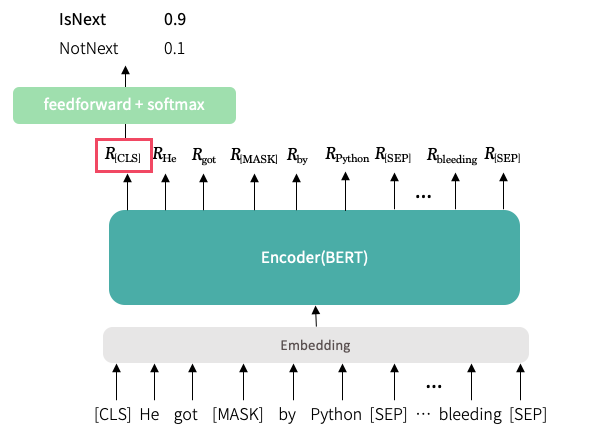
사전 학습 절차
- 말뭉치에서 두 문장 A, B를 샘플링한다.
- A와 B의 총 토큰 수의 합은 512보다 작거나 같아야 한다.
- 전체의 50%은 B 문장이 A 문장과 이어지는 문장(
IsNext)이 되도록 샘플링하고, 나머지 50%은 B 문장이 A 문장의 후속 문장이 아닌 것(NotNext)으로 샘플링한다.
- 워드피스 토크나이저로 문장을 토큰화하고, 토큰 임베딩-세그먼트 임베딩-위치 임베딩 레이어를 거친다.
- 시작 부분에
[CLS]토큰을, 문장 끝에[SEP]토큰을 추가한다. 80-10-10%규칙에 따라 토큰의 15%를 무작위 마스킹한다.
- 시작 부분에
- BERT에 토큰을 입력하고, MLM과 NSP 태스크를 동시에 수행한다.
- 웜업 스텝(= 1만): 초기 1만 스텝은 학습률이 0에서 1e - 4로 선형 증가, 1만 스텝 이후 선형 감소
- 드롭아웃(0.1) 사용
- GeLU 활성화 함수 사용: 음수에 대해서도 미분이 가능해 약간의 그래디언트를 전달할 수 있음
사전 학습의 효과
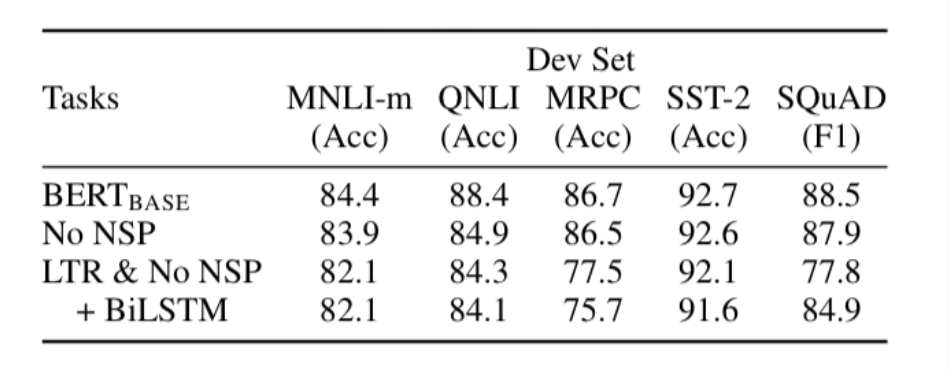
No NSP: MLM 사용 / NSP 미사용
LTR & No NSP: MLM 대신 Left-to-Right 사용 / NLP 미사용
- NSP 태스크를 진행하지 않으면 자연어 추론 태스크(QNLI, MNLI)와 QA 태스크(SQuAD)에서 큰 성능 하락이 있음
- MLM 대신 LTR이나 BiLSTM을 사용했을 때 MRPC와 SQuAD에서의 성능이 크게 하락함. MLM이 LTR과 BiLSTM보다 훨씬 깊은 양방향성을 띈다.
참고자료
'스터디 기록 > 구글 BERT의 정석' 카테고리의 다른 글
| [NLP] Sentence-BERT 살펴보기 (0) | 2022.04.09 |
|---|---|
| [구글 BERT의 정석] Chapter 6: 텍스트 요약을 위한 BERTSUM 탐색 (2) | 2022.02.27 |
| [NLP] ALBERT: A Lite BERT (0) | 2022.02.03 |